Learn how to fine-tune vision-language models on Fireworks AI with image and text datasets
VLM fine-tuning is currently supported for Qwen 2.5 VL models only.
This guide covers fine-tuning for Vision-Language Models (VLMs) that process both images and text. For fine-tuning text-only models, see our Supervised fine-tuning for text guide.
Vision-language model (VLM) fine-tuning allows you to adapt pre-trained models that can understand both text and images to your specific use cases.
This is particularly valuable for tasks like document analysis, visual question answering, image captioning, and domain-specific visual understanding.
This guide shows you how to fine-tune VLMs on Fireworks AI using LoRA (Low-Rank Adaptation) with datasets containing both images and text.
LoRA significantly reduces the computational and memory requirements for fine-tuning large vision-language models.
Instead of updating billions of parameters directly, LoRA learns small “adapter” layers that capture the changes needed for your specific task.
Key benefits of LoRA for VLMs:
Efficiency: Requires significantly less memory and compute than full fine-tuning
Speed: Faster training times while maintaining high-quality results
Flexibility: Up to 100 LoRA adaptations can run simultaneously on a dedicated deployment
Cost-effective: Lower training costs compared to full parameter fine-tuning
{"messages": [{"role": "system", "content": "You are a helpful visual assistant that can analyze images and answer questions about them."}, {"role": "user", "content": [{"type": "text", "text": "What objects do you see in this image?"}, {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD..."}}]}, {"role": "assistant", "content": "I can see a red car, a tree, and a blue house in this image."}]}
Images must be base64 encoded with MIME type prefixes.
If your dataset contains image urls, you will need to download and encode them to base64.
❌ Incorrect Format - This will NOT work:
Copy
Ask AI
{"messages": [{"role": "user", "content": [{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}, {"type": "text", "text": "What's in this image?"}]}, {"role": "assistant", "content": "I can see..."}]}
Raw HTTP/HTTPS URLs are not supported. Images must be base64 encoded.
✅ Correct Format - Use this instead:
Copy
Ask AI
{"messages": [{"role": "user", "content": [{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD..."}}, {"type": "text", "text": "What's in this image?"}]}, {"role": "assistant", "content": "I can see..."}]}
Notice the data:image/jpeg;base64, prefix followed by the base64 encoded image data.
You can use the following script to automatically convert your dataset to the correct format:
Python script to download and encode images to base64
Usage:
Copy
Ask AI
# Install required dependencypip install requests# Download the scriptwget https://raw.githubusercontent.com/fw-ai/cookbook/refs/heads/main/learn/vlm-finetuning/utils/download_images_and_encode_to_b64.py# Run the script - will output a new dataset <path_to_your_dataset>_base64.jsonlpython download_images_and_encode_to_b64.py --input_file <path_to_your_dataset.jsonl>
{ "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Compare these two images and tell me the differences" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,/9j/4AAQSkZJRg..." } }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,/9j/4BBBSkZJRg..." } } ] }, { "role": "assistant", "content": "The first image shows a daytime scene while the second shows the same location at night. The lighting and shadows are completely different." } ]}
{ "messages": [ { "role": "system", "content": "You are a helpful visual assistant that can analyze images and remember details from previous images in our conversation." }, { "role": "user", "content": [ { "type": "text", "text": "Can you describe this kitchen layout for me?" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQ..." } } ] }, { "role": "assistant", "content": "This is a modern open-plan kitchen with white cabinets, granite countertops, and stainless steel appliances. The island is positioned in the center with bar seating for 3-4 people. There's a large window above the sink providing natural light." }, { "role": "user", "content": "Now look at this living room. Do you think the styles would work well together?" }, { "role": "assistant", "content": "I'd be happy to help compare the styles! However, I don't see a living room image in your message. Could you please share the living room photo so I can analyze how well it would coordinate with the modern kitchen style we just discussed?" }, { "role": "user", "content": [ { "type": "text", "text": "Sorry about that! Here's the living room:" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,/9j/4BBBSkZJRgABAQ..." } } ] }, { "role": "assistant", "content": "Perfect! This living room has a complementary modern aesthetic that would work beautifully with the kitchen. Both spaces feature clean lines and a neutral color palette. The living room's contemporary furniture and the kitchen's sleek design would create a cohesive flow in an open floor plan. The warm wood accents in the living room would add nice contrast to the kitchen's cooler tones." }, ]}
2
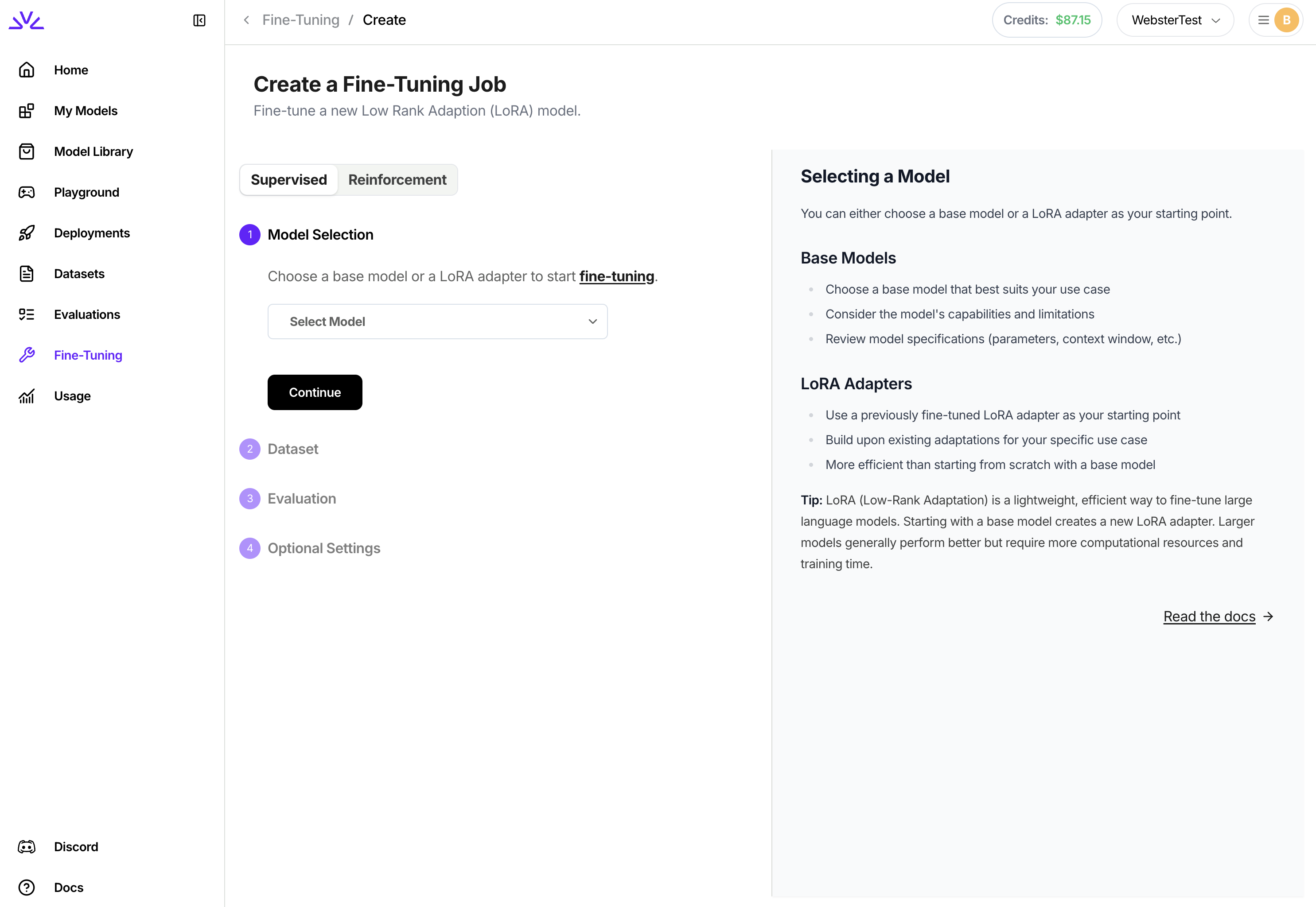
Upload your VLM dataset
Upload your prepared JSONL dataset to Fireworks for training:
Navigate to the Fine-tuning tab in the Fireworks console
Click “Create Fine-tuning Job”
Select your VLM base model (Qwen 2.5 VL)
Choose your uploaded dataset
Configure training parameters
Launch the job
VLM fine-tuning jobs typically take longer than text-only models due to the additional image processing. Expect training times of several hours depending on dataset size and model complexity.
4
Monitor training progress
Track your VLM fine-tuning job:
Copy
Ask AI
# Check job statusfirectl get sftj my-custom-vlm# View training logsfirectl get sftj my-custom-vlm --logs
Monitor key metrics:
Training loss: Should generally decrease over time
Validation loss: Monitor for overfitting if using evaluation dataset
Training progress: Epochs completed and estimated time remaining
Your VLM fine-tuning job is complete when the status shows COMPLETED and your custom model is ready for deployment.
5
Deploy your fine-tuned VLM
Once training is complete, deploy your custom VLM:
Copy
Ask AI
# Create a deployment for your fine-tuned VLMfirectl create deployment my-vlm-deployment --model my-custom-vlm# Check deployment statusfirectl get deployment my-vlm-deployment
For additional fine-tuning parameters and advanced settings like custom learning rates, batch sizes, and optimization options, see the Additional SFT job settings section in our comprehensive fine-tuning guide.