Fine-tuning a model using SFT
1
Confirm model support for fine-tuning
You can confirm that a base model is available to fine-tune by looking for the And looking for
Tunnable tag in the model library or by using:Tunable: true.Some base models cannot be tuned on Fireworks (
Tunable: false) but still list support for LoRA (Supports Lora: true). This means that users can tune a LoRA for this base model on a separate platform and upload it to Fireworks for inference. Consult importing fine-tuned models for more information.2
Prepare a dataset
Datasets must be in JSONL format, where each line represents a complete JSON-formatted training example. Make sure your data conforms to the following restrictions:We also support function calling dataset with a list of tools. An example would look like:For the subset of models that supports thinking (e.g. DeepSeek R1, GPT OSS models and Qwen3 thinking models), we also support fine tuning with thinking traces. If you wish to fine tune with thinking traces, the dataset could also include thinking traces for assistant turns. Though optional, ideally each assistant turn includes a thinking trace. For example:Note that when fine tuning with intermediate thinking traces, the number of total tuned tokens could exceed the number of total tokens in the dataset. This is because we perform preprocessing and expand the dataset to ensure train-inference consistency.
- Minimum examples: 3
- Maximum examples: 3 million per dataset
- File format:
.jsonl - Message schema: Each training sample must include a messages array, where each message is an object with two fields:
role: one ofsystem,user, orassistant. A message with thesystemrole is optional, but if specified, it must be the first message of the conversationcontent: a string representing the message contentweight: optional key with value to be configured in either 0 or 1. message will be skipped if value is set to 0
3
Create and upload a dataset
There are a couple ways to upload the dataset to Fireworks platform for fine tuning: While all of the above approaches should work,
firectl, Restful API , builder SDK or UI.- UI
- firectl
- Restful API
-
You can simply navigate to the dataset tab, click
Create Datasetand follow the wizard.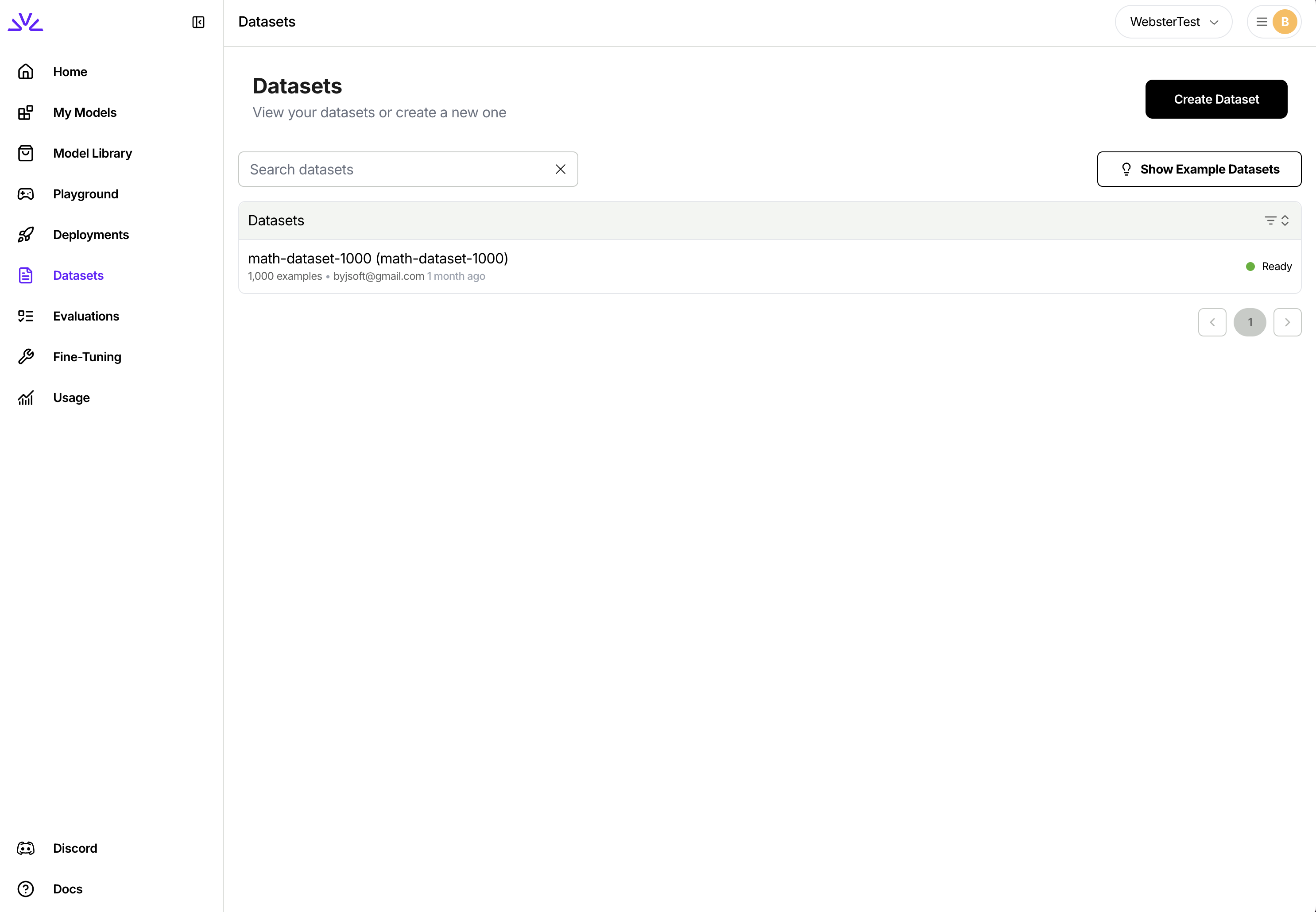
UI is more suitable for smaller datasets < 500MB while firectl might work better for bigger datasets.Ensure the dataset ID conforms to the resource id restrictions.4
Launch a fine-tuning job
There are also a couple ways to launch the fine-tuning jobs. We highly recommend creating supervised fine tuning jobs via With 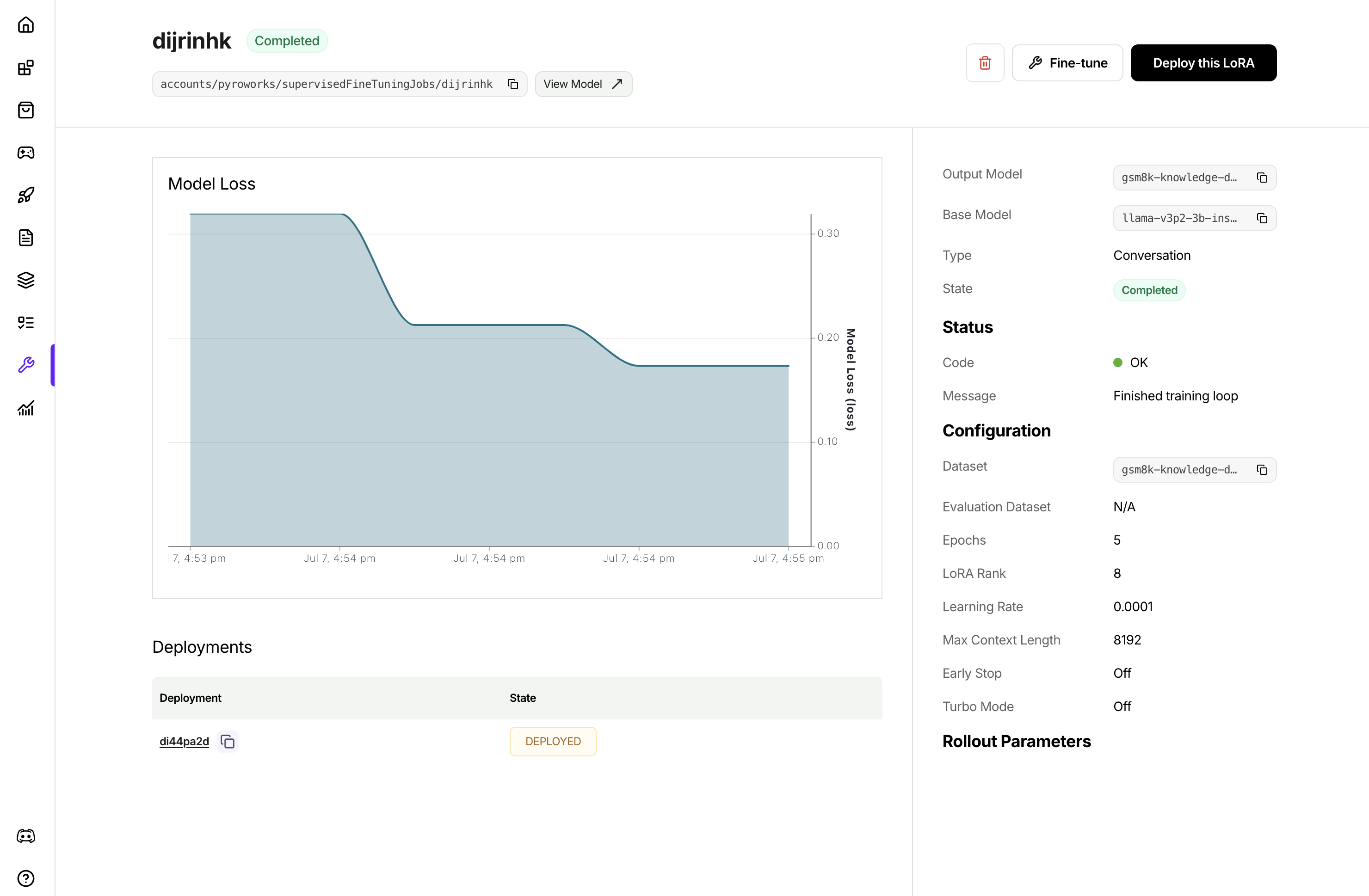
UI .- UI
- firectl
Simply navigate to the 
Fine-Tuning tab, click Fine-Tune a Model and follow the wizard from there. You can even pick a LoRA model to start the fine-tuning for continued training.UI, once the job is created, it will show in the list of jobs. Clicking to view the job details to monitor the job progress.firectl, you can monitor the progress of the tuning job by runningDeploying a fine-tuned model
After fine-tuning completes, deploy your model to make it available for inference:Additional SFT job settings
Additional tuning settings are available when starting a fine-tuning job. All of the below settings are optional and will have reasonable defaults if not specified. For settings that affect tuning quality likeepochs and learning rate, we recommend using default settings and only changing hyperparameters if results are not as desired.
Evaluation
Evaluation
By default, the fine-tuning job will run evaluation by running the fine-tuned model against an evaluation set that’s created by automatically carving out a portion of your training set. You have the option to explicitly specify a separate evaluation dataset to use instead of carving out training data.
evaluation_dataset: The ID of a separate dataset to use for evaluation. Must be pre-uploaded via firectlEarly stopping
Early stopping
Early stopping stops training early if the validation loss does not improve. It is off by default.
Max Context Length
Max Context Length
By default, fine-tuned models support a max context length of 8k. Increase max context length if your use case requires context above 8k. Maximum context length can be increased up to the default context length of your selected model. For models with over 70B parameters, we only support up to 65536 max context length.
Epochs
Epochs
Epochs are the number of passes over the training data. Our default value is 1. If the model does not follow the training data as much as expected, increase the number of epochs by 1 or 2. Non-integer values are supported.Note: we set a max value of 3 million dataset examples × epochs
Learning rate
Learning rate
Learning rate controls how fast the model updates from data. We generally do not recommend changing learning rate. The default value is automatically based on your selected model.
LoRA Rank
LoRA Rank
LoRA rank refers to the number of parameters that will be tuned in your LoRA add-on. Higher LoRA rank increases the amount of information that can be captured while tuning. LoRA rank must be a power of 2 up to 64. Our default value is 8.
Training progress and monitoring
Training progress and monitoring
The fine-tuning service integrates with Weights & Biases to provide observability into the tuning process. To use this feature, you must have a Weights & Biases account and have provisioned an API key.
Model ID
Model ID
By default, the fine-tuning job will generate a random unique ID for the model. This ID is used to refer to the model at inference time. You can optionally specify a custom ID, within ID constraints.
Job ID
Job ID
By default, the fine-tuning job will generate a random unique ID for the fine-tuning job. You can optionally choose a custom ID.
Turbo Mode
Turbo Mode
By default, the fine-tuning job will use a single GPU. You can optionally enable the turbo mode to accelerate with multiple GPUs (only for non-Deepseek models).
Appendix
Python builder SDK references
Restful API references
firectl references