
Optimizing Retrieval Augmented Generation (RAG) with MongoDB Atlas and Fireworks AI
By Fireworks.ai|3/21/2024
RAG is all the rage now! Haven’t heard about it? In this blog, we precisely help you kickstart your Generative AI Application development Journey and how to build a Retrieval Augmented Generation (RAG) App using MongoDB Atlas and Fireworks AI. Further we’ll discuss how to optimize the architecture to achieve better cost and performance.
In a post-ChatGPT world, hearing about a new AI advancement or a Large Language Model (LLM) as a developer is as common as a new Javascript framework. Playing around with LLMs is fun, but creating AI-enabled experiences is the real deal in skill building for any developer.
Building apps or experiences on pre-trained LLMs has limitations. GPT, Claude, Llama and Mixtral have their knowledge/learning cutoff at a specific date. Methods to add custom knowledge, like fine-tuning, also have restrictions, like cost and knowledge limits that are restricted to training data.
MongoDB and Fireworks have partnered together to help enterprises build the next generation of scalable, secure cost-effective RAG applications grounded in their operational data.
What is RAG?
Retrieval Augmented Generation (RAG) combines best of both worlds by leveraging a retrieval component to fetch relevant information from a database (or a vector store) and a generative component (LLM) to synthesize and generate a coherent response to the user query.
Through a RAG Architecture, LLMs get a second brain and the ability to fetch relevant and up-to-date info and turn the LLM into a real-time response generation engine that is grounded in your own data.
Why RAG?
Some more reasons that make a RAG App special are:
**Data Efficiency: **RAG is data-efficient because it dynamically pulls in relevant data or information that may not have been seen during training. This saves time, effort and money compared to more data-hungry solutions like fine-tuning, which also often demand specialist, hard to find skills.
**Flexibility: **RAG enables dynamic updating of underlying knowledge bases or documents, making it easier to maintain the model without regular retraining. It is beneficial when the domain information is changing frequently, like with stock prices, weather etc.
RAG Architecture
A RAG Architecture consists of a Large Language Model to synthesize and submit the query to a data store (also can be called a vector store). The vector store then returns the relevant vector chunks as response to the LLM’s initial request. The LLM absorbs the response into its context and generates a response relevant to the user’s query.
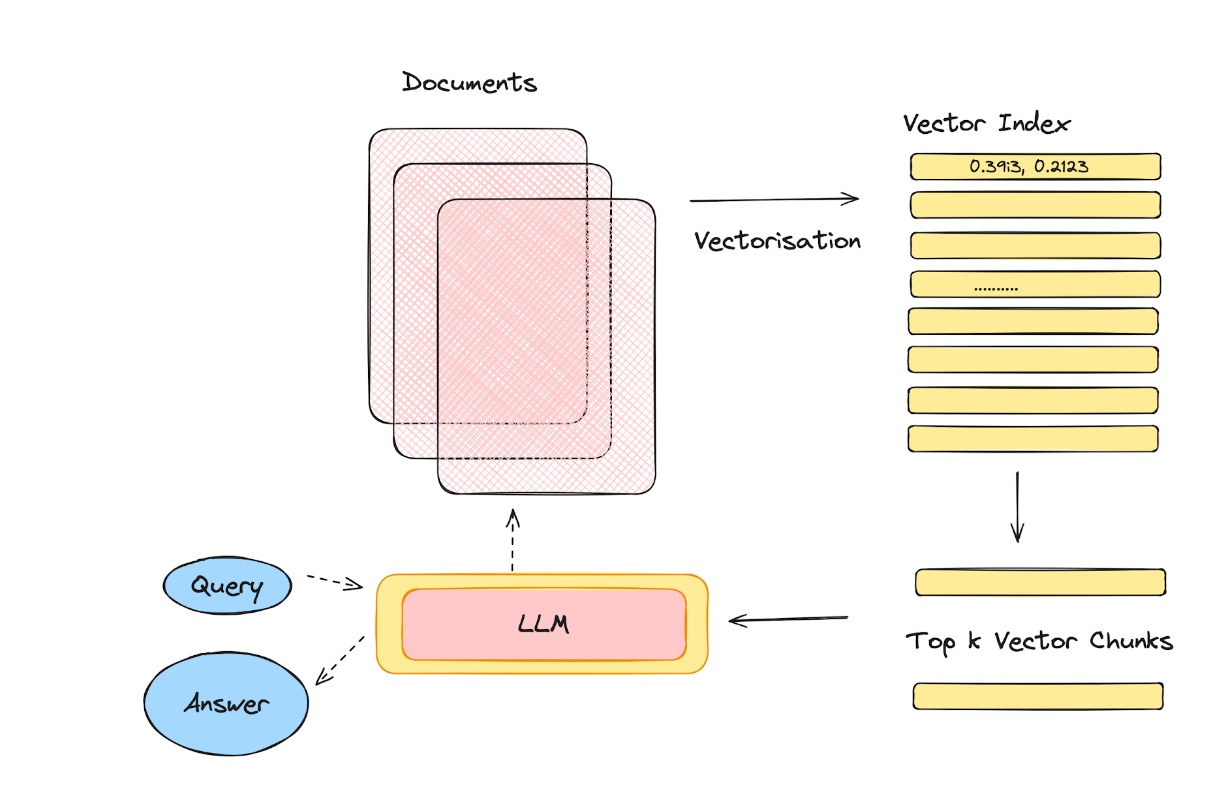
As mentioned in the beginning of the blog, we’ll create a RAG-based app which recommends movies based on the user’s query. We are going to build a model to index and retrieve movie recommendations. The example will be built on top of MongoDB and Fireworks AI and involves:
- MongoDB Atlas Database that indexes movies using embeddings. (Vector Store)
- A system for document embedding generation. We'll use the Fireworks embedding API to create embeddings from text data. (Vectorisation)
- MongoDB Atlas Vector Search that responds to user queries by converting the query to an embedding, fetching the corresponding movies. (Retrieval Engine)
- The Mixtral model using the Fireworks inference API to generate the recommendations. You can also use Llama, Gemma, and other great OSS models if you like. (LLM)
- Loading MongoDB Atlas Sample Mflix Dataset to generate embeddings (Dataset)
💡Note: You can further learn more about optimizing RAG architecture. We have some helpful tips to reduce costs, improve throughput, add batching, and introduce function calling. These options help customize and scale your RAG architecture to suit your specific needs.
Optimizing RAG architecture
While this tutorial focuses on building a basic RAG Pipeline, we have guides to build optimized RAG architectures that can be further customized and scaled to suit various needs. For example:
- Reduce the cost: Fireworks provides a range of embedding models with advanced capabilities. You can reduce the size of the embeddings, without a significant drop in retrieval performance, leading to reduced downstream costs associated with storing and retrieving embeddings. Improve the throughput: We are only documenting 400 movies in this example, which is not a lot. This is because we wanted to keep this tutorial simple and not batching the embedding lookups, and just have a for loop that goes through all the documents and embed them manually. This method does not scale. First, we will cover basic batching in the following guide.
- Tap into the rich AI ecosystem: MongoDB and Fireworks work great with the various tools and frameworks you may be already using. Food for thought! There are a lot of great frameworks that offer batching out of the box, and please check out our guides here for LlamaIndex and LangChain.
Prerequisites
- MongoDB Atlas Account
- Fireworks AI Account
Note: You can follow the tutorial using the Notebook
Configuring your environment
Before we dive into the code, make sure to set up your environment. This involves installing necessary packages like
pymongo, fireworks-ai and openai.
!pip install -q pymongo fireworks-ai tqdm openai
Note: We use the OpenAI Python SDK because it’s compatible with the Fireworks SDK
Gathering Credentials
To interact with Fireworks AI and MongoDB Atlas Cluster, we need to initialize their respective clients. Replace "FIREWORKS_API_KEY" and "MONGODB_URI" with your actual credentials.
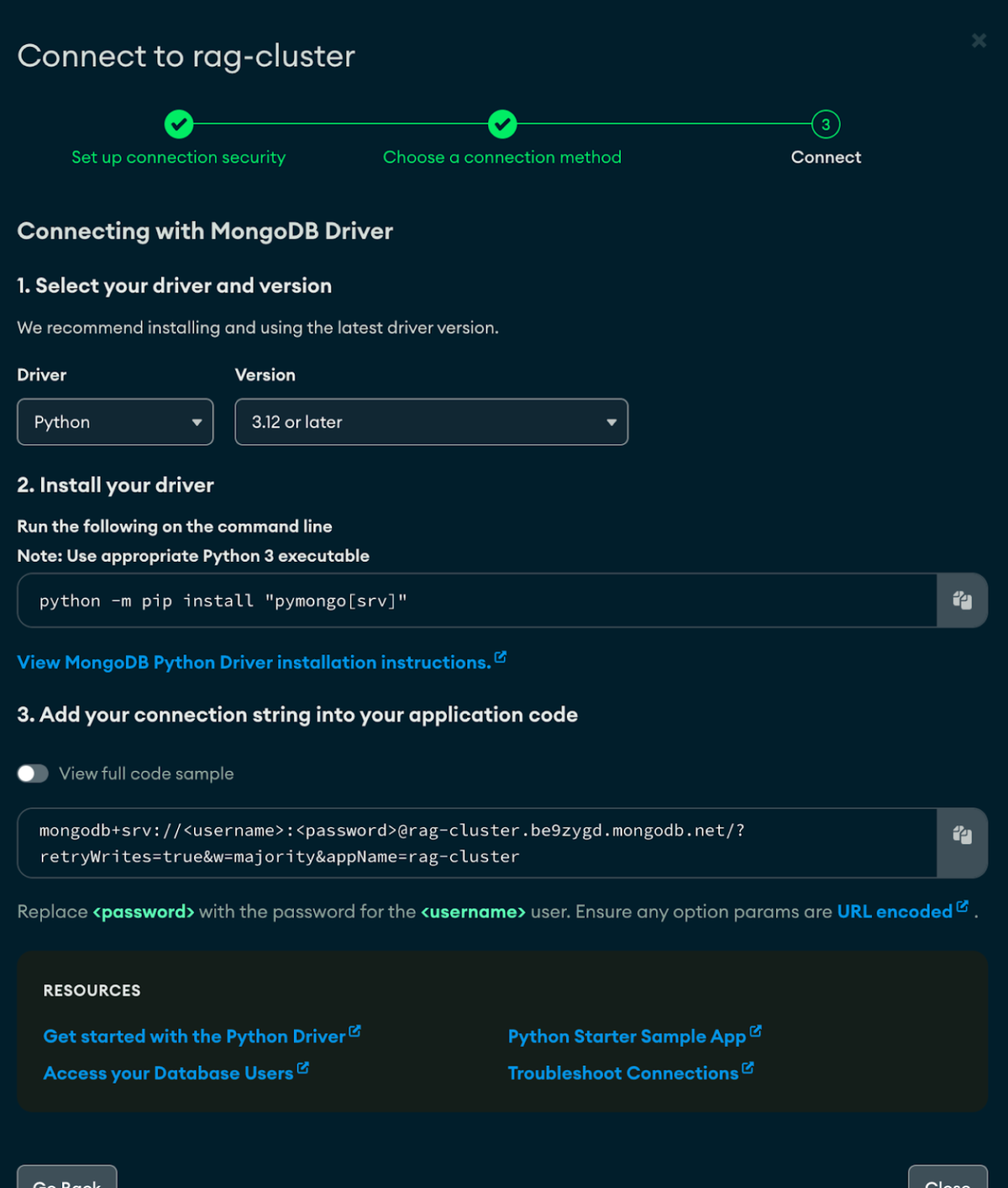
MongoDB Atlas
You can create and pick up the MongoDB URI from the MongoDB Atlas Cluster following the steps below.
Fireworks
After creating your account at Fireworks.ai, you can find the Fireworks API_Key under Account Settings
-> API Keys
Initializing Fireworks and MongoDB Clients
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
uri = "MONGODB_URI"
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
import openai
fw_client = openai.OpenAI(
api_key="FIREWORKS_API_KEY",
base_url="https://api.fireworks.ai/inference/v1"
)
Using Fireworks with OSS Embedding Models
Fireworks serves many state-of-the-art embedding models. Here are the full list of models Fireworks support.
- mixedbread-ai/mxbai-embed-large-v1 (current leader for OSS model on MTEB leaderboard, from Mixbread.ai)
- BAAI/bge-base-en-v1.5 (great embedding model from BAAI)
- nomic-ai/nomic-embed-text-v1.5 (great for Matryosha variable embedding dimension support)
- WhereIsAI/UAE-Large-V1
- thenlper/gte-large
- thenlper/gte-base
In this blog, we are using the Nomic AI Model as one example to generate embeddings from the document corpus,
specifically the [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) variant. The
function generate_embeddings below takes a list of texts and returns embeddings.
from typing import List
def generate_embeddings(input_texts: str, model_api_string: str, prefix="") -> List[float]:
"""Generate embeddings from Fireworks python library
Args:
input_texts: a list of string input texts.
model_api_string: str. An API string for a specific embedding model of your choice.
prefix: what prefix to attach to the generate the embeddings, which is required for nomic 1.5. Please check out https://huggingface.co/nomic-ai/nomic-embed-text-v1.5#usage for more information
Returns:
reduced_embeddings_list: a list of reduced-size embeddings. Each element corresponds to each input text.
"""
if prefix:
input_texts = [prefix + text for text in input_texts]
return fw_client.embeddings.create(
input=input_texts,
model=model_api_string,
).data[0].embedding
We will be adding more OSS embedding models as the space evolves, please check the fireworks.ai website for the most up to date list of embedding models.
Generating embeddings
Now, let's process our movie data through the generate_embeddings function created above.
We'll extract key information from our MongoDB collection and generate embeddings for each movie. Ensure NUM_DOC_LIMIT here is set to limit the number of documents processed.
embedding_model_string = 'nomic-ai/nomic-embed-text-v1.5'
vector_database_field_name = 'embed' # define your embedding field name.
NUM_DOC_LIMIT = 2000 # the number of documents you will process and generate embeddings.
sample_output = generate_embeddings(["This is a test."], embedding_model_string)
print(f"Embedding size is: {str(len(sample_output))}")
from tqdm import tqdm
from datetime import datetime
db = client.sample_mflix
collection = db.movies
keys_to_extract = ["plot", "genre", "cast", "title", "fullplot", "countries", "directors"]
for doc in tqdm(collection.find(
{
"fullplot":{"$exists": True},
"released": { "$gt": datetime(2000, 1, 1, 0, 0, 0)},
}
).limit(NUM_DOC_LIMIT), desc="Document Processing "):
extracted_str = "\n".join([k + ": " + str(doc[k]) for k in keys_to_extract if k in doc])
if vector_database_field_name not in doc:
doc[vector_database_field_name] = generate_embeddings([extracted_str], embedding_model_string, "search_document: ")
collection.replace_one({'_id': doc['_id']}, doc)
Creating a Index on MongoDB Collection
For our system to efficiently search through movie embeddings, we need to set up a search index in MongoDB. Define the index structure as shown:
"""
{
"fields": [
{
"type": "vector",
"path": "embed",
"numDimensions": 768,
"similarity": "dotProduct"
}
]
}
"""
Generating personalized recommendations with Fireworks
Querying the Recommender System
Let's test our recommender system. We create a query for superhero movies and exclude Spider-Man movies, as per user preference.
# Example query.
query = "I like Christmas movies, any recommendations?"
prefix="search_query: "
query_emb = generate_embeddings([query], embedding_model_string, prefix=prefix)
results = collection.aggregate([
{
"$vectorSearch": {
"queryVector": query_emb,
"path": vector_database_field_name,
"numCandidates": 100, # this should be 10-20x the limit
"limit": 10, # the number of documents to return in the results
"index": 'movie', # the index name you used in the earlier step
}
}
])
results_as_dict = {doc['title']: doc for doc in results}
print(f"From your query \"{query}\", the following movie listings were found:\n")
print("\n".join([str(i+1) + ". " + name for (i, name) in enumerate(results_as_dict.keys())]))
Generating Recommendations
Finally, we use Fireworks' chat API to generate a personalized movie recommendation based on the user's query and preferences.
your_task_prompt = (
"From the given movie listing data, choose a few great movie recommendation given the user query. "
f"User query: {query}"
)
listing_data = ""
for doc in results_as_dict.values():
listing_data += f"Movie title: {doc['title']}\n"
for (k, v) in doc.items():
if not(k in keys_to_extract) or ("embedding" in k): continue
if k == "name": continue
listing_data += k + ": " + str(v) + "\n"
listing_data += "\n"
augmented_prompt = (
"movie listing data:\n"
f"{listing_data}\n\n"
f"{your_task_prompt}"
)
response = fw_client.chat.completions.create(
messages=[{"role": "user", "content": augmented_prompt}],
model="accounts/fireworks/models/mixtral-8x7b-instruct",
)
print(response.choices[0].message.content)
What’s next?
We successfully built a movie recommendation system RAG using Fireworks, MongoDB, and the nomic-ai embedding model.
While this tutorial focuses on building a basic RAG Pipeline, we have guides to build optimized RAG architectures that can be further customized and scaled to suit various needs. For example:
- Tunable cost for storage: We used the default 768 embedding dimension in the example. There are cases where the cost for storing the embedding is high, and you might want to reduce that, and we will walk you through another example with MongoDB + leveraging Matryoshka embedding to reduce embedding size in this guide.
- Improve the functionality with Function calling: You may want to dynamically decide to do RAG depending on the user query, and construct different filters that would fulfill the user query on the fly. In that case, Fireworks offers one of the fastest function calling models for you to orchestrate your application logic on top of your RAG architecture. You can check out how to combine RAG with function calling in this guide, or from the MongoDB interactive RAG example in this blog.