Accessing the monitoring dashboard
After creating your RFT job, you’ll receive a dashboard link in the CLI output:- Go to Fireworks Dashboard
- Click Fine-Tuning in the sidebar
- Select your job from the list
Understanding the overview
The main dashboard shows your job’s current state and key metrics.Job status
PENDING
PENDING
Your job is queued waiting for GPU resources. Queue time depends on current demand and your account priority.Action: None needed. Job will start automatically when resources become available.
VALIDATING
VALIDATING
Fireworks is validating your dataset to ensure it meets format requirements and quality standards.Duration: Typically 1-2 minutesAction: None needed. If validation fails, you’ll receive specific error messages about issues in your dataset.
RUNNING
RUNNING
Training is actively in progress. Rollouts are being generated, evaluated, and the model is learning.Action: Monitor metrics and rollout quality. This is when you’ll watch reward curves improve.
COMPLETED
COMPLETED
Training finished successfully. Your fine-tuned model is ready for deployment.Action: Review final metrics, then deploy your model.
FAILED
FAILED
Training encountered an unrecoverable error and stopped.Action: Check error logs and troubleshooting section below. Common causes include evaluator errors, resource limits, or dataset issues.
CANCELLED
CANCELLED
You or another user manually stopped the job.Action: Review partial results if needed. Create a new job to continue training.
EARLY_STOPPED
EARLY_STOPPED
Training stopped automatically because the full epoch showed no improvement. All rollouts received the same scores, indicating no training progress.Action: This typically indicates an issue with your evaluator or training setup. Check that:
- Your evaluator is returning varied scores (not all 0s or all 1s)
- The reward function can distinguish between good and bad outputs
- The model is actually generating different responses
Key metrics at a glance
The overview panel displays:- Elapsed time: How long the job has been running
- Progress: Current epoch and step counts
- Reward: Latest mean reward from rollouts
- Model: Base model and output model names
- Resources: GPU allocation and utilization
Training metrics
Reward curves
The most important metric in RFT is the reward curve, which shows how well your model is performing over time. What to look for:- Upward trend - Model is learning and improving
- Plateauing - Model may have converged; consider stopping or adjusting parameters
- Decline - Potential issue with evaluator or training instability
- Spikes - Could indicate noisy rewards or outliers in evaluation
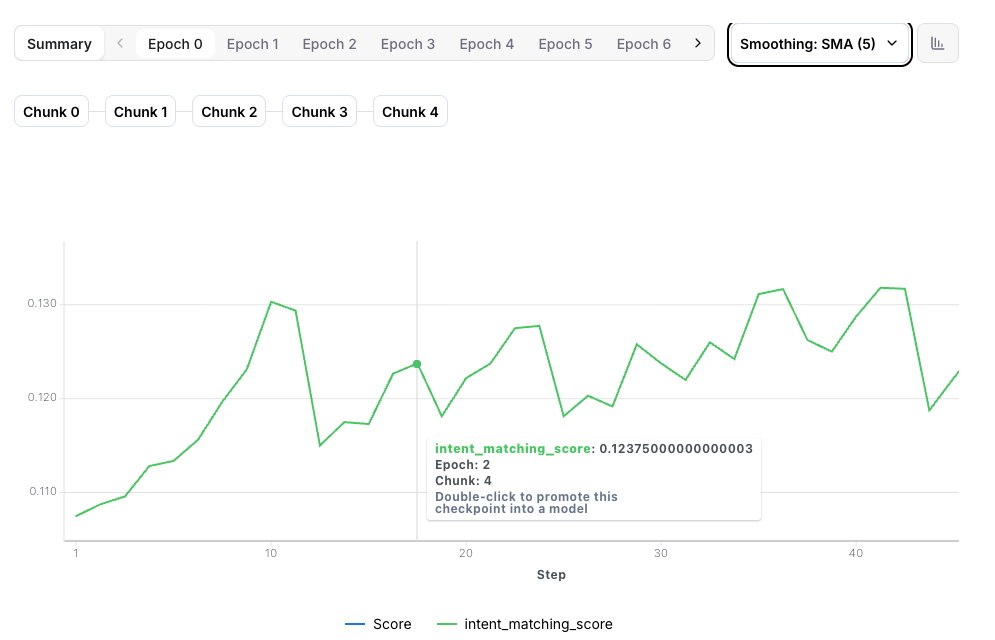
Healthy training shows steady reward improvement. Don’t worry about minor fluctuations—focus on the overall trend.
Training loss
Loss measures how well the model is fitting the training data:- Decreasing loss - Normal learning behavior
- Increasing loss - Learning rate may be too high
- Flat loss - Model may not be learning; check evaluator rewards
Evaluation metrics
If you provided an evaluation dataset, you’ll see validation metrics:- Eval reward: Model performance on held-out data
- Generalization gap: Difference between training and eval rewards
Large gaps between training and eval rewards suggest overfitting. Consider reducing epochs or adding more diverse training data.
Inspecting rollouts
Understanding individual rollouts helps you verify your evaluator is working correctly and identify quality issues.Rollout overview table
Click any Epoch in the training timeline, then click the table icon to view all rollouts for that step.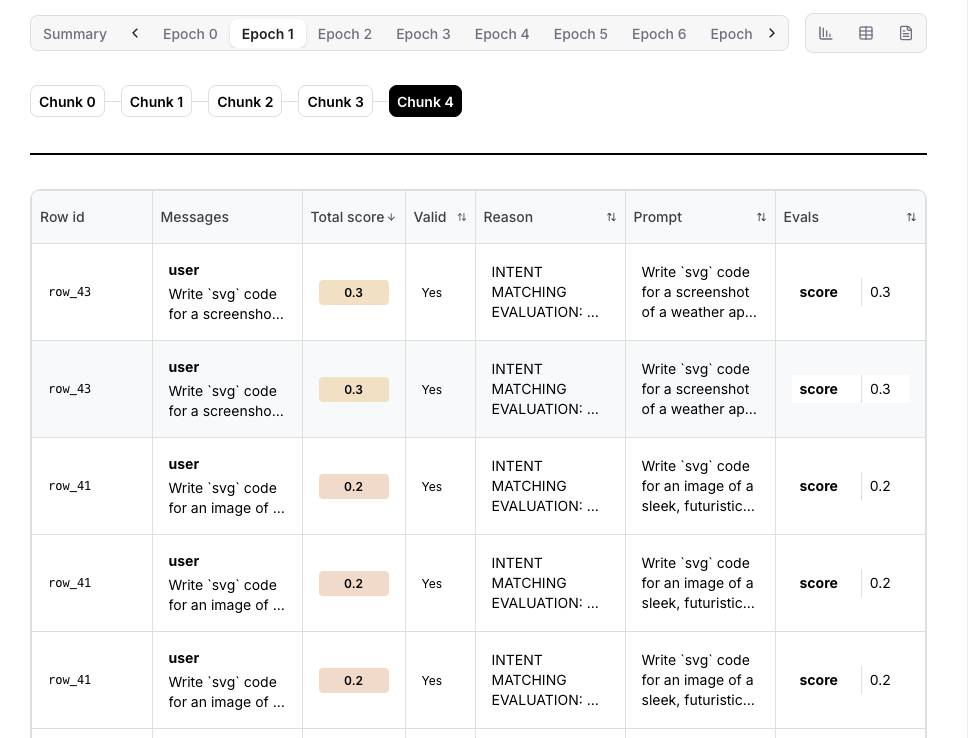
- Row ID: Unique identifier for each dataset row used in this rollout
- Prompt: The input prompt sent to the model
- Messages: The model’s generated response messages
- Valid: Whether the rollout completed successfully without errors
- Reason: Explanation if the rollout failed or was marked invalid
- Score: Reward score assigned by your evaluator (0.0 to 1.0)
- Most rollouts succeeding (status: complete)
- Reward distribution makes sense (high for good outputs, low for bad)
- Many failures indicate evaluator issues
- All rewards identical may indicate evaluator is broken
Individual rollout details
Click any row in the rollout table to see full details: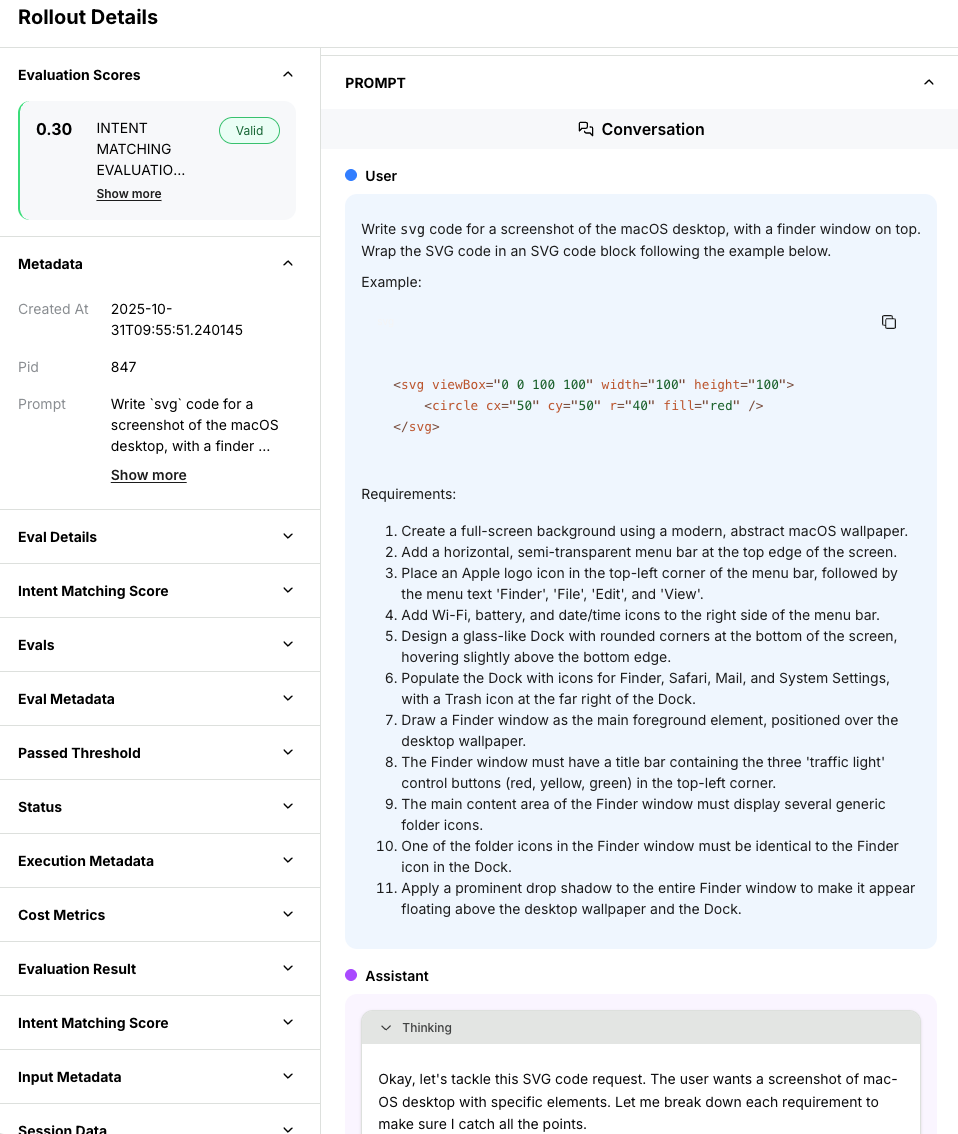
- Full prompt: Exact messages sent to the model
- Model response: Complete generated output
- Evaluation result: Reward score and reasoning (if provided)
- Metadata: Token counts, timing, temperature settings
- Tool calls: For agentic rollouts with function calling
Copy and paste model outputs to test them manually. For example, if you’re training a code generator, try running the generated code yourself to verify your evaluator is scoring correctly.
Quality spot checks
Regularly inspect rollouts at different stages of training: Early training (first epoch):- Verify evaluator is working correctly
- Check that high-reward rollouts are actually good
- Ensure low-reward rollouts are actually bad
- Confirm model quality is improving
- Look for new strategies or behaviors emerging
- Check that evaluator isn’t being gamed
- Verify final model quality meets your standards
- Check for signs of overfitting (memorizing training data)
- Ensure diversity in responses (not all identical)
Live logs
Real-time logs show what’s happening inside your training job.Accessing logs
Click the Logs icon next to the table icon to view real-time logs for your training job.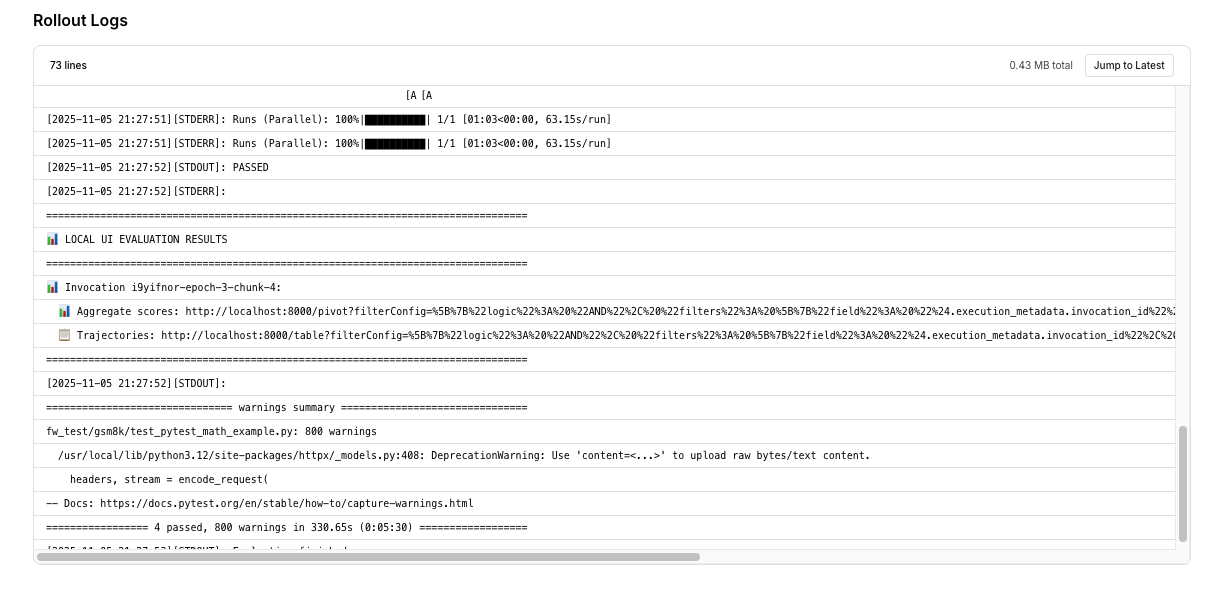
Using logs for debugging
When things go wrong, logs are your first stop:- Filter by error level: Focus on
[ERROR]and[WARNING]messages - Search for rollout IDs: Track specific rollouts through their lifecycle
- Look for patterns: Repeated errors indicate systematic issues
- Check timestamps: Correlate errors with metric changes
Common issues and solutions
Training stuck at low reward
Training stuck at low reward
Symptoms: Reward curve flat or very low throughout trainingPossible causes:
- Evaluator always returning 0 or very low scores
- Model outputs not matching expected format
- Task too difficult for base model
- Inspect rollouts to verify evaluator is working:
- Check that some rollouts get high rewards
- Verify reward logic makes sense
- Test evaluator locally on known good/bad outputs
- Simplify the task or provide more examples
- Try a stronger base model
Reward suddenly drops
Reward suddenly drops
Symptoms: Reward increases then crashes and stays lowPossible causes:
- Learning rate too high causing training instability
- Model found an exploit in the evaluator (reward hacking)
- Catastrophic forgetting
- Stop training and use the last good checkpoint
- Restart with lower learning rate (e.g.,
--learning-rate 5e-5) - Review recent rollouts for reward hacking behavior
- Improve evaluator to be more robust
Many rollout failures
Many rollout failures
Symptoms: Rollout table shows lots of errors or timeoutsPossible causes:
- Evaluator code errors
- Timeout too short for evaluation
- External API failures (for remote evaluators)
- Resource exhaustion
- Check error logs for specific error messages
- Test evaluator locally to reproduce errors
- Increase
--rollout-timeoutif evaluations need more time - Add better error handling in evaluator code
- For remote evaluators: check server health and logs
Training loss increases
Training loss increases
Symptoms: Loss goes up instead of downPossible causes:
- Learning rate too high
- Conflicting reward signals
- Numerical instability
- Reduce learning rate by 2-5x
- Check that rewards are consistent (same prompt gets similar rewards)
- Verify rewards are in valid range [0, 1]
- Consider reducing batch size
All rollouts identical
All rollouts identical
Symptoms: Model generates the same response for every promptPossible causes:
- Temperature too low (near 0)
- Model found one high-reward response and overfit to it
- Evaluator only rewards one specific output
- Increase
--inference-temperatureto 0.8-1.0 - Make evaluator more flexible to accept diverse good answers
- Use more diverse prompts in training data
- Reduce epochs to prevent overfitting
Remote evaluator timeouts
Remote evaluator timeouts
Symptoms: Many rollouts timing out with remote environmentPossible causes:
- Remote server slow or overloaded
- Network latency issues
- Evaluator not logging completion correctly
- Check remote server logs for errors
- Verify server is logging
Status.rollout_finished() - Increase
--rollout-timeoutto allow more time - Scale remote server to handle concurrent requests
- Optimize evaluator code for performance
Out of memory (OOM) errors
Out of memory (OOM) errors
Symptoms: Job fails with “CUDA out of memory” or similarPossible causes:
- Batch size too large for GPU
- Context length too long
- Model too large for allocated GPUs
- Reduce
--batch-size(e.g., from 65536 to 32768) - Reduce
--inference-max-tokensif responses are very long - Use smaller base model
- Request more GPUs with
--accelerator-count(via firectl)
Performance optimization
Speeding up training
If training is slower than expected:Optimize evaluator speed
Optimize evaluator speed
Slow evaluators directly increase training time:
- Profile your evaluator code to find bottlenecks
- Cache expensive computations
- Use batch processing for API calls
- Add timeouts to prevent hanging
Adjust rollout parameters
Adjust rollout parameters
Reduce compute while maintaining quality:
- Decrease
--inference-n(e.g., from 8 to 4 rollouts per prompt) - Reduce
--inference-max-tokensif responses don’t need to be long - Lower temperature slightly to speed up sampling
Scale infrastructure
Scale infrastructure
For remote evaluators:
- Add more worker instances to handle concurrent rollouts
- Use faster machines (more CPU, memory)
- Optimize network connectivity to Fireworks
- Request more GPUs via account settings
- Use faster base models for initial experiments
Cost optimization
Reduce costs without sacrificing too much quality:- Start small: Experiment with
qwen3-0p6bbefore scaling to larger models - Reduce rollouts: Use
--inference-n 4instead of 8 - Shorter responses: Lower
--inference-max-tokensto minimum needed - Fewer epochs: Start with 1 epoch, only add more if needed
- Efficient evaluators: Minimize API calls and computation
Stopping and resuming jobs
Stopping a running job
If you need to stop training:- Click Cancel Job in the dashboard
- Or via CLI:
Cancelled jobs cannot be resumed. If you want to continue training, create a new job starting from the last checkpoint.
Using checkpoints
Checkpoints are automatically saved during training. To continue from a checkpoint:- Extending training after early stopping
- Trying different hyperparameters on a trained model
- Building on previous successful training runs
Comparing multiple jobs
Running multiple experiments? Compare them side-by-side:- Navigate to Fine-Tuning dashboard
- Select multiple jobs using checkboxes
- Click Compare
- Reward curves overlaid on same graph
- Parameter differences highlighted
- Final metrics comparison
- Training time and cost comparison
Use consistent naming for experiments (e.g.,
math-lr-1e4, math-lr-5e5) to make comparisons easier.Exporting metrics
For deeper analysis or paper writing:Via dashboard
- Click Export button in job view
- Choose format: CSV, JSON
- Select metrics to export (rewards, loss, rollout data)
Via API
Weights & Biases integration
If you enabled W&B when creating the job:Best practices
Monitor early, monitor often
Monitor early, monitor often
Check your job within the first 15-30 minutes of training:
- Verify evaluator is working correctly
- Confirm rewards are in expected range
- Catch configuration errors early
Spot check rollouts regularly
Spot check rollouts regularly
Every few epochs, inspect 5-10 random rollouts:
- Manually verify high-reward outputs are actually good
- Check low-reward outputs are actually bad
- Look for unexpected model behaviors
Save successful configurations
Save successful configurations
When you find good hyperparameters, save the command:Makes it easy to reproduce results or share with team.
Use meaningful names
Use meaningful names
Name jobs descriptively:
- Good:
math-solver-llama8b-temp08-n8 - Bad:
test1,try2,final-final
Document experiments
Document experiments
Keep notes on what worked and what didn’t:
- Hypothesis for each experiment
- Parameters changed
- Results and insights
- Next steps